What are runs?
A run is created when you trigger a task (e.g. callingyourTask.trigger({ foo: "bar" })). It represents a single instance of a task being executed and contains the following key information:
- A unique run ID
- The current status of the run
- The payload (input data) for the task
- Lots of other metadata
The run lifecycle
A run can go through various states during its lifecycle. The following diagram illustrates a typical state transition where a single run is triggered and completes successfully: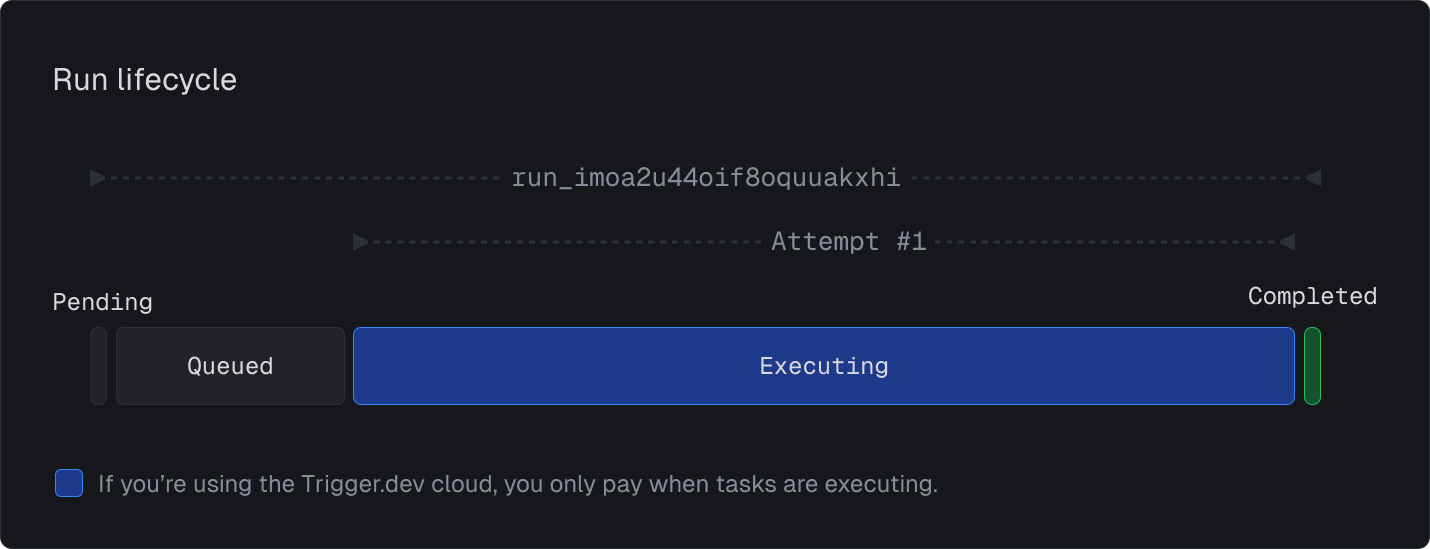 Runs can also find themselves in lots of other states depending on what’s happening at any given time. The following sections describe all the possible states in more detail.
Runs can also find themselves in lots of other states depending on what’s happening at any given time. The following sections describe all the possible states in more detail.
Initial States
Waiting for deploy: If a task is triggered before it has been deployed, the run enters this state and waits for the task to be deployed. Delayed: When a run is triggered with a delay, it enters this state until the specified delay period has passed. Queued: The run is ready to be executed and is waiting in the queue.Execution States
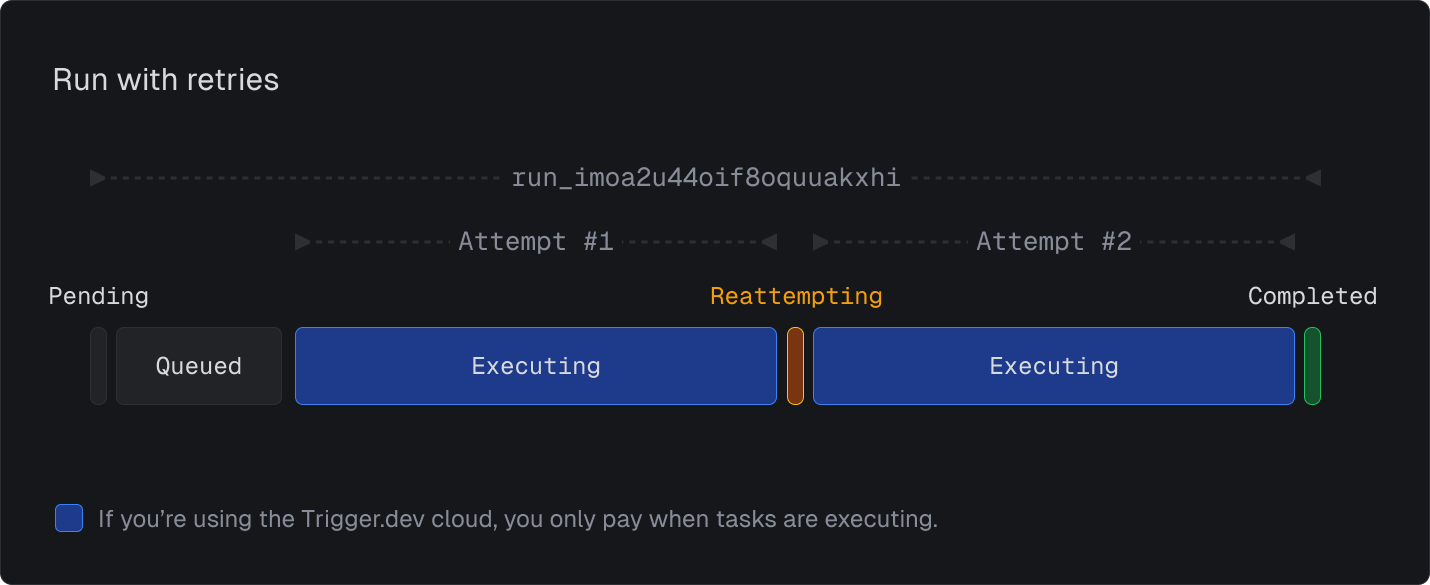
Executing: The task is currently running. Reattempting: The task has failed and is being retried. Waiting: You have used a triggerAndWait(), batchTriggerAndWait() or a wait function. When the wait is complete, the task will resume execution.Final States
Completed: The task has successfully finished execution. Canceled: The run was manually canceled by the user. Failed: The task has failed to complete successfully. Timed out: Task has failed because it exceeded itsmaxDuration.
Crashed: The worker process crashed
during execution (likely due to an Out of Memory error).
Interrupted: In development
mode, when the CLI is disconnected.
System failure: An unrecoverable system
error has occurred.
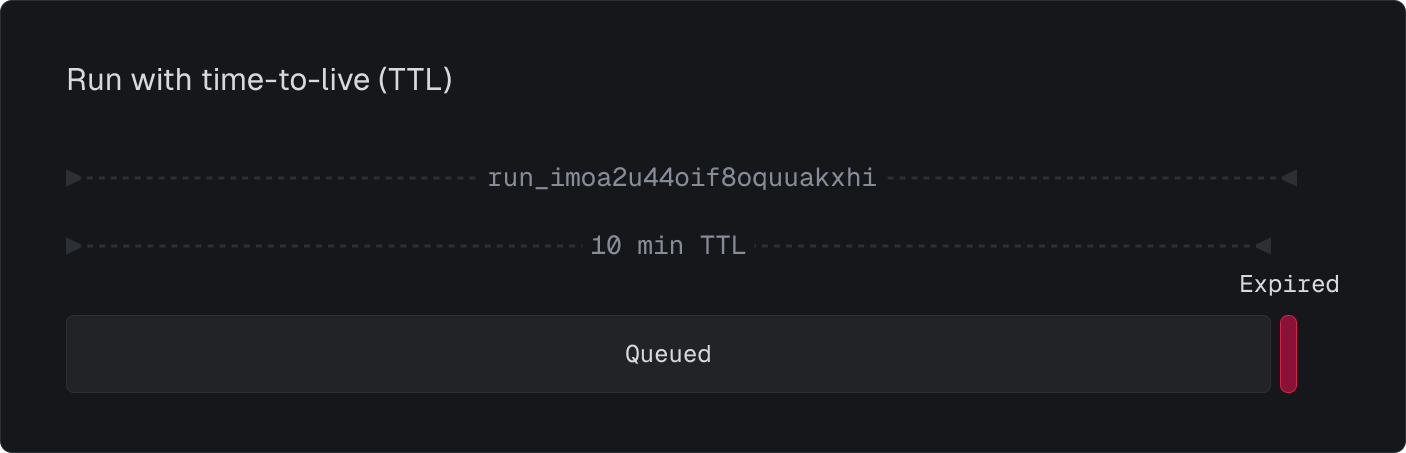
Expired: The run’s Time-to-Live
(TTL) has passed before it could start executing.
Attempts
An attempt represents a single execution of a task within a run. A run can have one or more attempts, depending on the task’s retry settings and whether it fails. Each attempt has:- A unique attempt ID
- A status
- An output (if successful) or an error (if failed)
Run completion
A run is considered finished when:- The last attempt succeeds, or
- The task has reached its retry limit and all attempts have failed
Advanced run features
Idempotency Keys
When triggering a task, you can provide an idempotency key to ensure the task is executed only once, even if triggered multiple times. This is useful for preventing duplicate executions in distributed systems.- If a run with the same idempotency key is already in progress, the new trigger will be ignored.
- If the run has already finished, the previous output or error will be returned.
Canceling runs
You can cancel an in-progress run using the API or the dashboard:Time-to-live (TTL)
TTL is a time-to-live setting that defines the maximum duration a run can remain in a queued state before being automatically expired. You can set a TTL when triggering a run:Expired. This is useful for time-sensitive tasks where immediate execution is important. For example, when you queue many runs simultaneously and exceed your concurrency limits, some runs might be delayed - using TTL ensures they only execute if they can start within your specified timeframe.
Note that dev runs automatically have a 10-minute TTL. In Staging and Production environments, no TTL is set by default.
Delayed runs
You can schedule a run to start after a specified delay: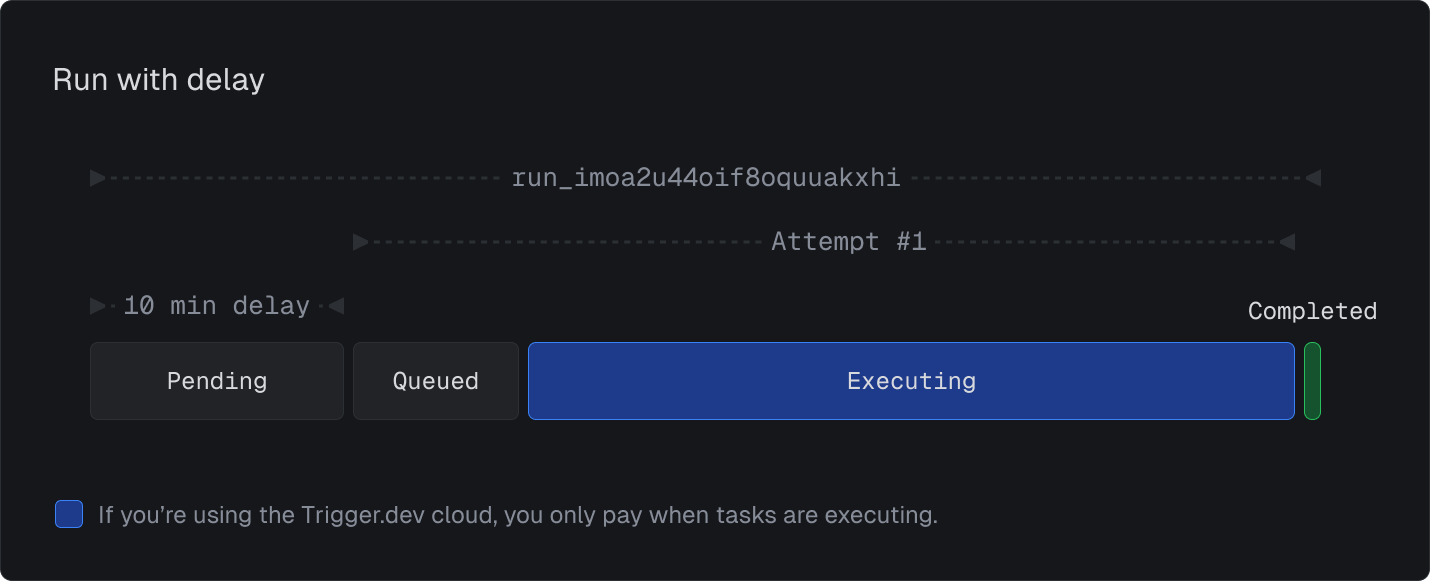
Replaying runs
You can create a new run with the same payload as a previous run:Waiting for runs
triggerAndWait()
ThetriggerAndWait() function triggers a task and then lets you wait for the result before continuing. Learn more about triggerAndWait().
.png)
batchTriggerAndWait()
Similar totriggerAndWait(), the batchTriggerAndWait() function lets you batch trigger a task and wait for all the results Learn more about batchTriggerAndWait().
.png)
Runs API
runs.list()
List runs in a specific environment. You can filter the runs by status, created at, task identifier, version, and more:list() function to narrow down the results:
runs.retrieve()
Fetch a single run by it’s ID:run.payload and run.output:
retrieve() and the response will already be typed:
runs.cancel()
Cancel a run:runs.replay()
Replay a run:runs.reschedule()
Updates a delayed run with a new delay. Only valid when the run is in the DELAYED state.Real-time updates
Subscribe to changes to a specific run in real-time:runs.retrieve(), you can provide the type of the task to correctly type the run.payload and run.output: